
Are LLMs Plateauing? No. You Are.
When you test frontier models on yesterday’s benchmarks, you’ll miss today’s breakthroughs. You're weighing an elephant with a bathroom scale.

“GPT-5 isn’t that impressive.” People claim the jump from GPT4o to GPT-5 feels incremental.
They’re wrong. LLM intelligence hasn’t plateaued. Their perception of intelligence has.
How We Mistake Benchmark Saturation for Stagnation
Let me explain with a simple example: translation from French to English.
GPT-4o was already at 100% accuracy for this task. Near-perfect translations, proper idioms, cultural context. Just nailed it.
Now try GPT-o1, o3, GPT-5, or whatever comes next. The result? Still 100% accurate.
From your perspective, nothing changed. Zero improvement. The model looks identical. They have plateaued.
But here’s the thing: most people’s tasks are dead simple.
- “Do this math for me”
- “Explain this concept”
- “Translate this text”
- “Rewrite that email”
These tasks were already saturated by earlier models. They are testing intelligence on problems that have already been solved. Of course they don’t see progress.
They are like someone measuring a rocket’s speed with a car speedometer. Once you hit the max reading, everything looks the same.
Intelligence Is Task-Dependent
Intelligence is multi-dimensional. It’s a spectrum of capabilities tested against increasingly difficult tasks.
Think about how we measure human intelligence:
- A 5-year-old doing addition → Smart kid
- A PhD solving differential equations → Brilliant mathematician
- A Fields Medalist proving novel theorems → Genius
Same concept, wildly different difficulty levels. You wouldn’t judge the mathematician by giving them 2+2.
Yet that’s exactly what we’re doing with LLMs. We test them on tasks that earlier models already maxed out, then declare progress has stopped.
Where Intelligence Actually Progresses: The Frontier
Raw LLM intelligence is exploding. But it’s happening at the frontier. On tasks that push the absolute limits of reasoning.
Take GPT-5-Pro. It demonstrated the ability to produce novel mathematical proofs. Not “solve this known problem.” Not “explain this proof.” Create new mathematics.
Example: In an experiment by Sébastien Bubeck, GPT-5-Pro improved a bound in convex optimization from 1/L to 1.5/L. It reasoned for 17 minutes to generate a correct proof for an open problem.
Read that again. An LLM improved a mathematical bound. It generated original research. This isn’t just solving known problems. The AI is creating new knowledge.
We’re approaching a world where AI models will tackle the hardest unsolved problems in mathematics. The Millennium Prize Problems. P vs NP. The Riemann Hypothesis. Problems that have stumped humanity’s greatest minds for decades or centuries.
This isn’t incremental. This is a model operating at the level of professional mathematicians. And this capability emerged in the latest generation.
But if you’re only asking it to “explain gradient descent” or “fix my Python bug,” you’ll never see this intelligence. You’re testing a Formula 1 car in a parking lot.
Current Models Are Already Smarter Than Most Humans
Current frontier models (GPT-5-Pro, Claude 4.5) can already outperform most humans on most intellectual tasks. Not “simple” tasks. Most tasks.
- Legal analysis? Better than most lawyers.
- Medical diagnosis? Better than most doctors
- Code review? Better than most senior engineers.
- Financial modeling? Better than most analysts.
And they do it in seconds. No fatigue. No ego. No “I need to look that up.” (also no close to no compensation, lol!)
Soon, these models will be smarter than most humans combined. The collective intelligence of humanity, accessible in a chat interface.
But here’s what’s missing today: the ability to work over time with tools.
The Real Breakthrough: Using Tools
A human doesn’t rely on raw brain power alone. You use tools:
- Reading text to gather information
- Writing to organize thoughts
- Maintaining todo lists to track objectives
- Asking for feedback to improve
- Using calculators, spreadsheets, databases, software.
Your brain isn’t that powerful in isolation. Your intelligence emerges from orchestrating tools toward a goal.
LLMs sucked at this. They were brilliant in a single conversation but couldn’t persist, iterate, or coordinate across time.
That’s changing.
Agents: Intelligence That Persists
The breakthrough isn’t smarter models. It’s models that can orchestrate their intelligence over time.
Software engineers experienced that firsthand with coding agents. GPT-5-Codex, an open-source coding agent, can read, edit, execute code autonomously.
For instance, to refactor a 12,000-line legacy Python project, it will:
- Address dependencies
- Add test coverage
- Fix three race conditions
- Run for 7 hours in a sandboxed environment
This isn’t “write me a function.” This is sustained, multi-step reasoning with tool use. Planning, executing, validating, iterating.
The model maintained context, managed a todo list, ran tests, read errors, and adapted. Just like a human engineer would.
That’s the leap. Not raw intelligence but applied intelligence. It will take over most valuable knowledge worker jobs.
The AI Productivity Index (APEX)
Here’s where it gets real: the AI Productivity Index (APEX), the first benchmark for assessing whether frontier AI models can perform knowledge work with high economic value.
APEX addresses a massive inefficiency in AI research: outside of coding, most benchmarks test toy problems that don’t reflect real work. APEX changes that.
APEX-v1.0 contains 200 test cases across four domains:
- Investment banking
- Management consulting
- Law
- Primary medical care
How it was built:
1. Source experts with top-tier experience (e.g., Goldman Sachs investment bankers)
2. Experts create prompts reflecting high-value tasks from their day-to-day work
3. Experts create rubrics for evaluating model responses
This isn’t “explain what a stock is.” It’s “analyze this M&A deal structure and identify regulatory risks in cross-border jurisdictions.”
The results? Current models can already answer a significant portion of these questions. Not all, but enough to be economically valuable.
What’s missing isn’t intelligence. It’s agentic behavior.
Take stock research for instance. A model can read a 10-K filing and answer questions about it perfectly. At my company Fintool we saturated that benchmark in 2024.
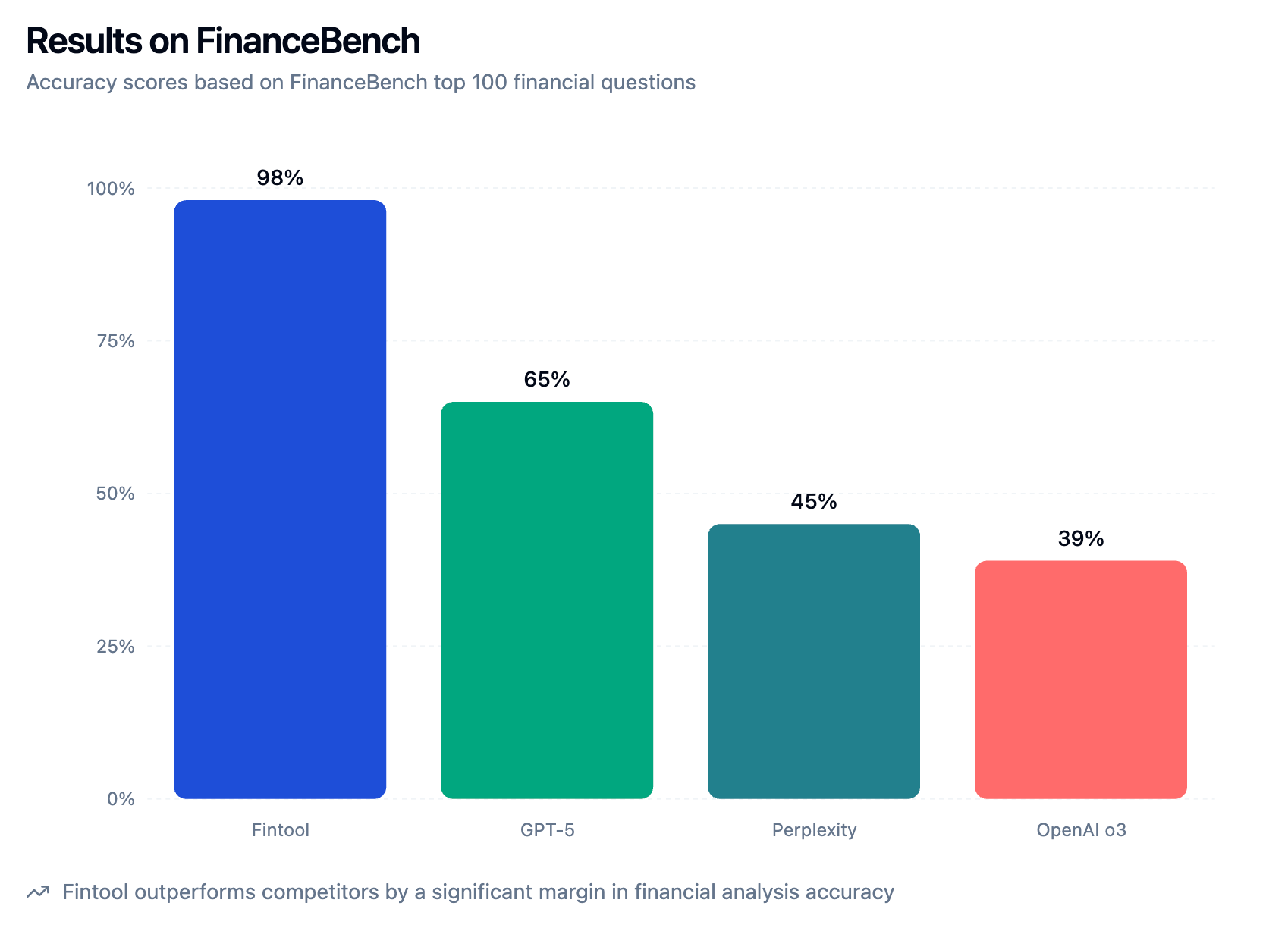
But now the challenge is for our AI to do investor’s job:
- Monitor earnings calls across hundreds of companies
- Extract precise financial metrics and projections
- Generate comprehensive research reports
- Compare performance across competitors
- Track industry trends over time
- Identify investment opportunities autonomously
Same “intelligence,” radically different capability. The raw LLM power is enhanced with tools. When we tested Fintool-v4 against human equity analysts we found that our agent was 25x faster and 183x cheaper, with 90% accuracy on expert-level tasks.
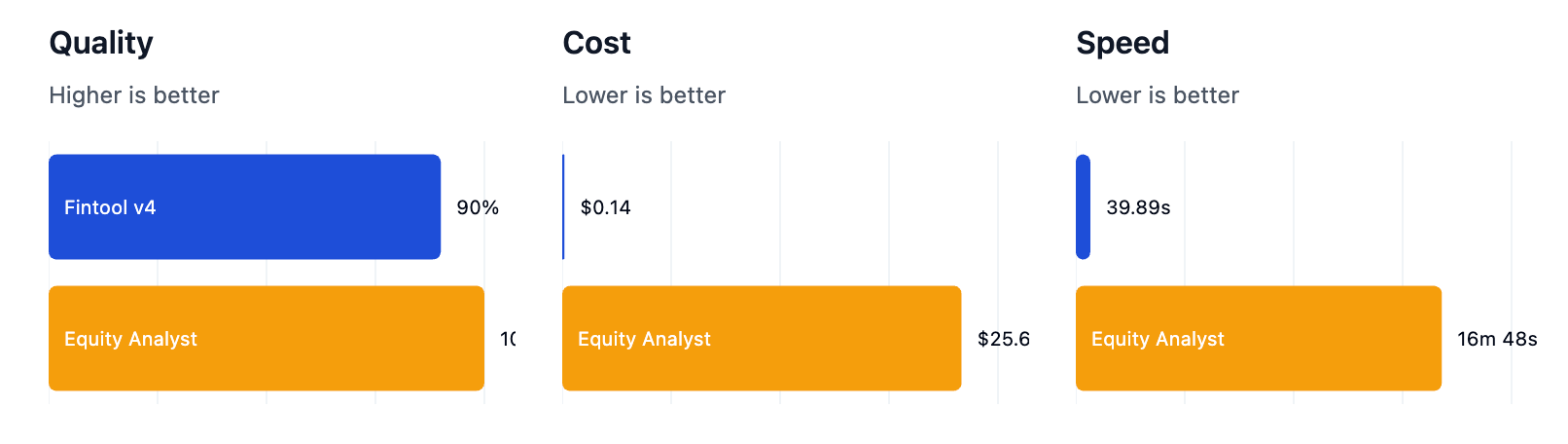
What Happens Next
The plateau isn’t in the model. It’s in your benchmark.
The next wave isn’t smarter models, it’s models that can actually do things. Even if raw intelligence plateaued tomorrow, expanding agentic capabilities alone would trigger massive economic growth. It’s about:
- Models that can maintain todo lists and execute over weeks
- Models that can read documentation, try solutions, fail, and iterate
- Models that can coordinate with other models and humans
- Models that can ask for help when stuck
And when millions of these agents are deployed, the world changes. Not because the models got smarter. Because they got useful.
Intelligence without application is just a party trick. Intelligence with tool use is the revolution.
It’s accelerating. Exponentially. But the real action is happening at the edge.
Beautiful analysis, as Karpathy highlighted agentic behaviors is next frontier - Still think contextualization is a big challenge rn to improve on real world complex tasks (window size + proper data contexts).
Wonderful post